Red Hat Enterprise Linux поставляется с большим набором инструментом для мониторинга ресурсов. Хотя ниже перечислены далеко не все инструменты, перечисленные здесь являются хорошими представителями своего класса с точки зрения функциональности:
free
top (и Системный монитор GNOME (GNOME System Monitor) — версия top, больше ориентированная на графическую среду)
vmstat
Sysstat — набор инструментов для мониторинга ресурсов
OProfile — средство профилирования на уровне системы
Давайте рассмотрим их подробнее.
2.5.1. free
Команда free выводит информацию об использовании памяти. Ниже показан пример её работы:
total used free shared buffers cached Mem: 255508 240268 15240 0 7592 86188 -/+ buffers/cache: 146488 109020 Swap: 530136 26268 503868
В строке Mem: показано использование физической памяти, в строке Swap: — использование пространства подкачки, а в строке -/+ buffers/cache: — объём физической памяти, выделенный в настоящее время для буферов системы.
Так как free по умолчанию выводит сведения об использовании памяти всего один раз, она годится только для очень непродолжительного наблюдения или быстрого определения, нет ли в данный момент проблем, связанных с памятью. Хотя free может выводить показатели использования памяти неоднократно (с параметром -s), выводимая информация прокручивается, что мешает увидеть, как меняются эти показатели.
 | Подсказка |
|---|---|
Поэтому вместо free -s лучше запустить free с помощью команды watch. Например, чтобы показатели использования памяти выводились каждые две секунды (интервал по умолчанию в watch), выполните команду: watch free Команда watch каждые две секунды выполняет команду free, очищает экран и выводит новую информацию в то же место на экране. Благодаря этому, следить за тем, как меняются показатели использования памяти, гораздо проще, так как watch создаёт одну обновляемую область просмотра без прокрутки. Вы можете менять задержку между обновлениями с помощью параметра -n, или сделать так, чтобы любые отличия результатов выделялись, указав параметр -d, как показано в следующей команде: watch -n 1 -d free За дополнительнымии сведениями обратитесь к странице руководства man watch. Команда watch будет работать, пока вы не прервёте её, нажав |
2.5.2. top
Тогда как команда free выводит только информацию, связанную с памятью, top сообщает понемногу обо всём. Использование процессора, статистика процессов, использование памяти — top контролирует всё. Кроме этого, в отличие от команды free, top по умолчанию работает непрерывно, так что использовать команду watch нет необходимости. Вот что она выводит:
14:06:32 up 4 days, 21:20, 4 users, load average: 0.00, 0.00, 0.00
77 processes: 76 sleeping, 1 running, 0 zombie, 0 stopped
CPU states: cpu user nice system irq softirq iowait idle
total 19.6% 0.0% 0.0% 0.0% 0.0% 0.0% 180.2%
cpu00 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 100.0%
cpu01 19.6% 0.0% 0.0% 0.0% 0.0% 0.0% 80.3%
Mem: 1028548k av, 716604k used, 311944k free, 0k shrd, 131056k buff
324996k actv, 108692k in_d, 13988k in_c
Swap: 1020116k av, 5276k used, 1014840k free 382228k cached
PID USER PRI NI SIZE RSS SHARE STAT %CPU %MEM TIME CPU COMMAND
17578 root 15 0 13456 13M 9020 S 18.5 1.3 26:35 1 rhn-applet-gu
19154 root 20 0 1176 1176 892 R 0.9 0.1 0:00 1 top
1 root 15 0 168 160 108 S 0.0 0.0 0:09 0 init
2 root RT 0 0 0 0 SW 0.0 0.0 0:00 0 migration/0
3 root RT 0 0 0 0 SW 0.0 0.0 0:00 1 migration/1
4 root 15 0 0 0 0 SW 0.0 0.0 0:00 0 keventd
5 root 34 19 0 0 0 SWN 0.0 0.0 0:00 0 ksoftirqd/0
6 root 35 19 0 0 0 SWN 0.0 0.0 0:00 1 ksoftirqd/1
9 root 15 0 0 0 0 SW 0.0 0.0 0:07 1 bdflush
7 root 15 0 0 0 0 SW 0.0 0.0 1:19 0 kswapd
8 root 15 0 0 0 0 SW 0.0 0.0 0:14 1 kscand
10 root 15 0 0 0 0 SW 0.0 0.0 0:03 1 kupdated
11 root 25 0 0 0 0 SW 0.0 0.0 0:00 0 mdrecoverydИнформация представлена в двух разделах. В верхнем разделе показаны общие сведения о состоянии системы — время работы, средняя нагрузка, число процессов, состояние процессора и статистика использования памяти и пространства подкачки. В нижнем разделе показана статистика в разрезе процессов. При этом в процессе работы top можно выбрать, какие данные будут отображаться. Например, по умолчанию top выводит статистику и по работающим, и по простаивающим процессам. Чтобы оставить только работающие процессы, нажмите
 | Предупреждение |
|---|---|
Хотя может показаться, что top — простая программа, способная только показывать статистику, это не так. На самом деле top воспринимает односимвольные команды и может выполнять различные действия. Например, если вы являетесь root, вы можете менять приоритет любых процессов в системе и даже уничтожать их. Поэтому, пока вы не изучили справку по командам top (чтобы её вызвать, надо нажать |
2.5.2.1. Системный монитор GNOME — top для графической среды
Если вам удобнее работать в графическом интерфейсе, возможно, вам больше понравится Системный монитор GNOME. Как и top, Системный монитор GNOME показывает общие сведения о состоянии системы, число процессов использование памяти и пространства подкачки, а также статистику по процессам.
Однако Системный монитор GNOME делает ещё один шаг и предлагает графическое представление использования процессора, памяти и пространства подкачки, а также в виде таблицы показывает, как используется дисковое пространство. Пример того, как в Системном мониторе GNOME выглядит вкладка Список процессов (Process Listing) показан на рисунке 2-1.
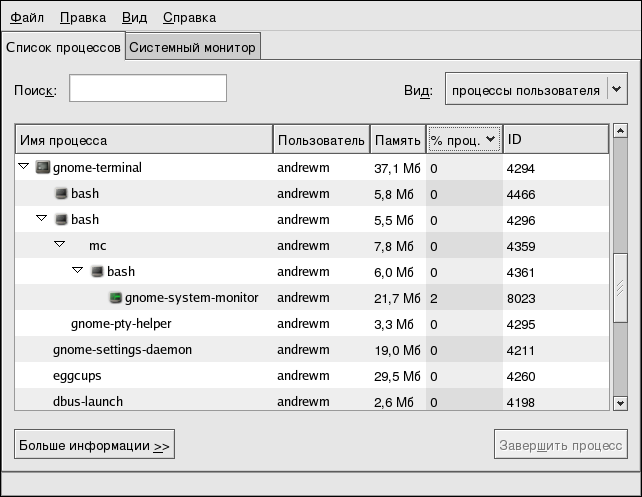
Дополнительную информацию об интересующем процессе можно получить, выделив этот процесс и нажав кнопку Больше информации (More Info).
Чтобы просмотреть показатели использования процессора, памяти и диска, перейдите на вкладку Системный монитор (System Monitor).
2.5.3. vmstat
Если вы хотите получить данные производительности в более сжатом виде, попробуйте vmstat. Команда vmstat выводит в одной строке набор чисел, отражающих активность процессов, памяти, механизма подкачки, ввода/вывода, системы и процессора:
procs memory swap io system cpu
r b swpd free buff cache si so bi bo in cs us sy id wa
0 0 5276 315000 130744 380184 1 1 2 24 14 50 1 1 47 0
В первой строке поля делятся на шесть категорий, а именно, статистику процессов, памяти, механизма подкачки, ввода/вывода, системы и процессора. Во второй строке содержимое каждого поля определяется точнее, чтобы нужный показатель можно было найти быстрее.
С процессами связаны поля:
r — Число исполняемых процессов, ждущих выделения процессорного времени
b — Число процессов, находящихся в непрерываемом спящем режиме
С памятью связаны поля:
swpd — Объём используемой виртуальной памяти
free — Объём свободной памяти
buff — Объём памяти, используемой для буферов
cache — Объём памяти, используемой в качестве кэша страниц
С подкачкой связаны поля:
si — Объём памяти, подкачанной с диска
so — Объём памяти, выгруженной на диск
С подсистемой ввода/вывода связаны поля:
bi — Количество блоков, отправленных на блочное устройство
bi — Количество блоков, полученных с блочного устройства
С системой связаны поля:
in — Количество прерываний в секунду
cs — Количество переключений контекста в секунду
С процессором связаны поля:
us — Время исполнения процессором кода уровня пользователя (в процентах от общего времени)
sy — Время исполнения процессором кода уровня системы (в процентах от общего времени)
id — Время простоя процессора (в процентах от общего времени)
wa — Время ожидания ввода/вывода
Если команда vmstat запущена без параметров, она выводит только одну строку показателей. Эта строка содержит средние значения за всё время работы системы после загрузки.
Однако большинство системных администраторов не доверяют этим данным, так как время, за которое они были собраны, непостоянно. Вместо этого большинство администраторов пользуются возможностью vmstat продолжать вывод данных использования ресурсов через заданный период времени. Например, команда vmstat 1 выводит новую строку с данными каждую секунду, а команда vmstat 1 10 также выводит новую строку каждую секунду, но только в течение следующих десяти секунд.
С помощью vmstat опытный администратор может быстро определить, как используются ресурсы, и выявить проблемы производительности. Но чтобы взглянуть внутрь этих проблем, требуется инструмент другого типа — инструмент, позволяющий собрать и проанализировать данные на более глубоком уровне.
2.5.4. Sysstat — набор инструментов для мониторинга ресурсов
Хотя описанные ранее инструменты могут быть полезны для анализа производительности системы в течение короткого периода времени, их возможности ограничиваются созданием снимков использования системных ресурсов. Кроме этого, есть аспекты производительности системы, наблюдать за которыми с помощью таких простых инструментов затруднительно.
Поэтому необходим более совершенный инструмент. И таким инструментом является Sysstat.
Sysstat содержит следующие средства, связанные со сбором статистики ввода/вывода и процессора:
- iostat
Выводит краткую статистику использования процессора, а также статистику ввода/вывода для одного или нескольких дисков.
- mpstat
Выводит более подробную статистику использования процессора.
Sysstat также включает средства сбора показателей использования ресурсов и построения на их основе ежедневных отчётов. Это следующие инструменты:
- sadc
sadc (System Activity Data Collector, сборщик данных активности системы) собирает информацию об использовании ресурсов системы и сохраняет их в файле.
- sar
Обрабатывая файлы, созданные sadc, sar может создавать интерактивные отчёты или сохранять их в файле для более подробного анализа.
В следующих разделах эти инструменты рассматриваются более подробно.
2.5.4.1. Команда iostat
Команда iostat в самом простом виде представляет краткую статистику использования процессора и дисковых операций ввода/вывода:
Linux 2.4.20-1.1931.2.231.2.10.ent (pigdog.example.com) 07/11/2003
avg-cpu: %user %nice %sys %idle
6.11 2.56 2.15 89.18
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
dev3-0 1.68 15.69 22.42 31175836 44543290
Под первой строкой (показывающей версию ядра системы, имя узла и текущую дату), iostat показывает, как в среднем использовался процессор после загрузки системы. Отчёт об использовании процессора включает следующие процентные отношения:
Время работы в режиме пользователя (исполняемых приложений и т.п.)
Время работы в режиме пользователя (процессов, с приоритетом, изменённым при помощи nice(2))
Время работы в режиме ядра
Время простоя
Затем приведён отчёт об использовании устройств. Этот отчёт включает отдельную строку для каждого активного дискового устройства компьютера и содержит следующие сведения:
Обозначение устройства, выводимое в виде dev<старший номер>-последовательный номер, где <старший номер> — старший номер устройства [1], а <последовательный номер> — порядковый номер, начиная с 0.
Число операций передачи данных (или операций ввода/вывода) в секунду.
Число блоков (размером 512 байт), прочитанных за секунду.
Число блоков (размером 512 байт), записанных за секунду.
Общее число прочитанных блоков (размером 512 байт).
Общее число записанных блоков (размером 512 байт).
Это всего лишь часть сведений, которые можно получить с помощью iostat. За дополнительной информацией обратитесь к странице руководства man iostat(1).
2.5.4.2. Команда mpstat
На первый взгляд команда mpstat выводит тот же отчёт об использовании процессора, что и iostat:
Linux 2.4.20-1.1931.2.231.2.10.ent (pigdog.example.com) 07/11/2003
07:09:26 PM CPU %user %nice %system %idle intr/s
07:09:26 PM all 6.40 5.84 3.29 84.47 542.47
За исключением дополнительного столбца, показывающего число прерываний, обработанных процессором за секунду, серьёзных отличий нет. Однако, ситуация меняется, если команде mpstat передаётся параметр -P ALL:
Linux 2.4.20-1.1931.2.231.2.10.ent (pigdog.example.com) 07/11/2003
07:13:03 PM CPU %user %nice %system %idle intr/s
07:13:03 PM all 6.40 5.84 3.29 84.47 542.47
07:13:03 PM 0 6.36 5.80 3.29 84.54 542.47
07:13:03 PM 1 6.43 5.87 3.29 84.40 542.47
На многопроцессорных компьютерах mpstat позволяет получить статистику использования процессоров по отдельности, благодаря чему можно определить, насколько эффективно используется каждый процессор.
2.5.4.3. Команда sadc
Как было сказано ранее, команда sadc собирает данные использования компьютера и сохраняет их в файле для дальнейшего анализа. По умолчанию данные сохраняются в файлах, в каталоге /var/log/sa/. Файлы имеют названия sa<dd>, где <dd> — текущий день месяца, представленный двумя цифрами.
Команда sadc обычно запускается сценарием sa1. А этот сценарий периодически вызывается демоном cron, благодаря файлу sysstat, расположенному в каталоге /etc/cron.d/. Сценарий sa1 вызывает sadc для выполнения одного измерения в течение одной секунды. По умолчанию cron запускает sa1 раз в 10 минут, и накапливает собранные в этом интервале данные в текущем файле /var/log/sa/sa<dd>.
2.5.4.4. Команда sar
Команда sar обрабатывает данные, собранные командой sadc, и на их основе формирует отчёты об использовании компьютера. В Red Hat Enterprise Linux команда sar по умолчанию автоматически запускает обработку файлов, созданных командой sadc. Файлы отчётов записываются в каталог /var/log/sa/ и называются sar<dd>, где <dd> день месяца предыдущего дня, представленный двумя цифрами.
Команда sar обычно запускается сценарием sa2. А этот сценарий периодически вызывается демоном cron, благодаря файлу sysstat, расположенному в каталоге /etc/cron.d/. По умолчанию cron запускает sa2 раз в день, в 23:53, благодаря чему отчёт формируется по данным всего прошедшего дня.
2.5.4.4.1. Формат отчётов sar
Отчёт sar, сформированный в настроенной по умолчанию системе Red Hat Enterprise Linux, состоит из нескольких разделов, при этом каждый раздел содержит данные определённого типа, отсортированные по времени сбора данных. Так как sadc выполняет измерения длительностью в одну секунду каждые десять минут, время сбора данных в отчёты sar по умолчанию последовательно увеличивается по 10 минут, с 00:00 до 23:50 [2].
Каждый раздел отчёта начинается с заголовка, описывающего содержащиеся в этом разделе данные. Заголовок повторяется на протяжении раздела через определённые интервалы, что очень облегчает восприятие данных при постраничном просмотре отчёта. В конце каждого раздела представлена строка, содержащая усреднённые значения всех данных, собранных в этом разделе.
Ниже приведён пример раздела sar, в котором данные с 00:30 по 23:40 убраны для экономии места:
00:00:01 CPU %user %nice %system %idle
00:10:00 all 6.39 1.96 0.66 90.98
00:20:01 all 1.61 3.16 1.09 94.14
…
23:50:01 all 44.07 0.02 0.77 55.14
Average: all 5.80 4.99 2.87 86.34
В этом разделе выводятся сведения об использовании процессора. Это очень похоже на то, что выводит iostat.
В других разделах могут к одной точке во времени могут относиться несколько строк данных, как в следующем разделе с данными использования процессора, собранными на двухпроцессорном компьютере:
00:00:01 CPU %user %nice %system %idle
00:10:00 0 4.19 1.75 0.70 93.37
00:10:00 1 8.59 2.18 0.63 88.60
00:20:01 0 1.87 3.21 1.14 93.78
00:20:01 1 1.35 3.12 1.04 94.49
…
23:50:01 0 42.84 0.03 0.80 56.33
23:50:01 1 45.29 0.01 0.74 53.95
Average: 0 6.00 5.01 2.74 86.25
Average: 1 5.61 4.97 2.99 86.43
Всего в отчётах, формируемых sar в стандартной конфигурации Red Hat Enterprise Linux, представлено 17 различных разделов, некоторые из них будут рассмотрены в следующих главах. За дополнительными сведениями о содержащихся в каждом разделе данных, обратитесь к странице man sar(1).
2.5.5. OProfile
OProfile — средство профилирования на уровне системы, оказывающее минимальное влияние на её работу. OProfile позволяет выявить природу проблем производительности, используя встроенные в процессор аппаратные возможности мониторинга производительности [3].
Оборудование мониторинга производительности является частью самого процессора. Оно принимает форму специального счётчика, увеличивающегося при определённом событии (например, при исполнении процессором инструкций или отсутствии запрашиваемых данных в кэше). Некоторые процессоры имеют несколько таких счётчиков и позволяют выбирать для каждого счётчика разные типы событий.
Счётчики могут иметь некоторое начальное значение и вызывать прерывание при переполнении. Задавая разные начальные значения счётчика, можно определить частоту, с какой будут происходить прерывания. Так можно управлять частотой выборки, а значит уровнем детализации собираемых данных.
Если задать для счётчика такое значение, что прерывание переполнения будет формироваться при каждом событии, собираемые данные будут предельно точны (но накладные расходы будут огромны). Может быть и другая крайность, когда счётчик вызывает прерывания максимально редко и даёт только общее представление о производительности компьютера (практически без накладных расходов). Секрет эффективного наблюдения состоит в правильном выборе частоты выборки, достаточной для выборки требуемых данных, но не настолько высокой, чтобы сопутствующие накладные расходы негативно отразились на производительности.
| Предупреждение |
|---|---|
OProfile вполне можно настроить так, что создаваемая им нагрузка сделает систему неработоспособной. Таким образом, выбирая значения счётчиков, вы должны быть внимательны. Поэтому команда opcontrol принимает параметр --list-events, который выводит типы событий, поддерживаемые текущим процессором, а также минимальные рекомендуемые значения счётчиков для каждого. |
Используя OProfile, важно не забывать о балансе между частотой выборки и сопутствующими накладными расходами.
2.5.5.1. Компоненты OProfile
Oprofile состоит из следующих компонентов:
Программные средства сбора данных
Программные средства анализа данных
Административный интерфейс
Программные средства сбора данных состоят из модуля ядра oprofile.o и демона oprofiled.
Средства анализа данных включают следующие программы:
- op_time
Выводит число и относительное процентное отношение выборок, сделанных для отдельных исполняемых файлов
- oprofpp
Выводит число и относительное процентное отношение выборок, сделанных отдельно взятыми функциями, отдельными инструкциями, или показатели в стиле gprof
- op_to_source
Выводит прокомментированный исходный код и/или листинг на ассемблере
- op_visualise
Выводит собранные данные в графическом виде
Эти программы позволяют просмотреть собранные данные самыми разными способами.
Административный интерфейс управляет всеми аспектами сбора данных, начиная с выбора отслеживаемых событий и заканчивая запуском и остановкой процесса сбора. Это осуществляется с помощью команды opcontrol.
2.5.5.2. Пример сеанса OProfile
Этот раздел демонстрирует сеанс наблюдения и анализа данных в OProfile, от начальной настройки до окончательного анализа данных. Это всего лишь вводный обзор, чтобы узнать об этом подробнее, обратитесь к Руководству по администрированию Red Hat Enterprise Linux.
Чтобы определить, какие типы данных должны собираться, воспользуйтесь opcontrol следующим образом:
opcontrol \
--vmlinux=/boot/vmlinux-`uname -r` \
--ctr0-event=CPU_CLK_UNHALTED \
--ctr0-count=6000Использованные здесь параметры указывают opcontrol:
Направить OProfile к копии текущего работающего ядра (--vmlinux=/boot/vmlinux-`uname -r`)
Использовать 0-ой счётчик процессора для отслеживания времени, в течение которого процессор выполнял инструкции (--ctr0-event=CPU_CLK_UNHALTED)
Указать OProfile делать выборки через каждые 6000 повторений заданного события (--ctr0-count=6000)
Затем проверьте, загружен ли модуль ядра oprofile, выполнив команду lsmod:
Module Size Used by Not tainted oprofile 75616 1 …
Убедитесь в том, что файловая система OProfile (расположенная в /dev/oprofile/) смонтирована, выполнив команду ls /dev/oprofile/:
0 buffer buffer_watershed cpu_type enable stats 1 buffer_size cpu_buffer_size dump kernel_only
(Точное количество файлов зависит от типа процессора.)
В данный момент файл /root/.oprofile/daemonrc содержит параметры, необходимые средствам сбора данных:
CTR_EVENT[0]=CPU_CLK_UNHALTED CTR_COUNT[0]=6000 CTR_KERNEL[0]=1 CTR_USER[0]=1 CTR_UM[0]=0 CTR_EVENT_VAL[0]=121 CTR_EVENT[1]= CTR_COUNT[1]= CTR_KERNEL[1]=1 CTR_USER[1]=1 CTR_UM[1]=0 CTR_EVENT_VAL[1]= one_enabled=1 SEPARATE_LIB_SAMPLES=0 SEPARATE_KERNEL_SAMPLES=0 VMLINUX=/boot/vmlinux-2.4.21-1.1931.2.349.2.2.entsmp
Затем воспользуйтесь opcontrol, чтобы начать сам процесс сбора данных, выполнив команду opcontrol --start:
Using log file /var/lib/oprofile/oprofiled.log Daemon started. Profiler running.
Убедитесь в том, что демон oprofiled работает, выполнив команду ps x | grep -i oprofiled:
32019 ? S 0:00 /usr/bin/oprofiled --separate-lib-samples=0 … 32021 pts/0 S 0:00 grep -i oprofiled
(Вообще командная строка oprofiled, которую показывает ps, намного длиннее, однако здесь она была сокращена с целью сохранения форматирования.)
При этом начинается наблюдение за системой и сбор данных по всем представленным в системе исполняемым модулям. Эти данные сохраняются в каталоге /var/lib/oprofile/samples/. Имена файлов в этом каталоге следуют несколько необычному соглашению. Например:
}usr}bin}less#0
В имени отражается абсолютный путь файла, содержащего исполняемый код, при этом символы косой черты (/) заменяются открывающими фигурными скобками (}), а в конце добавляется знак решётки (#) и число (в данном случае 0). Таким образом, в файле с именем, рассмотренном в этом примере, представлены данные, собранные во время работы /usr/bin/less.
Собрав данные, вы можете просмотреть их, воспользовавшись одним из средств анализа. У OProfile есть замечательная особенность — для выполнения анализа данных не обязательно прекращать сбор данных. Однако вы должны подождать, пока на диск не запишется хотя бы один набор выборок, или выполнить команду opcontrol --dump, чтобы принудительно записать выборки на диск.
В следующем примере для отображения собранных данных используется op_time (при этом данные отсортированы по убыванию количества выборок):
3321080 48.8021 0.0000 /boot/vmlinux-2.4.21-1.1931.2.349.2.2.entsmp 761776 11.1940 0.0000 /usr/bin/oprofiled 368933 5.4213 0.0000 /lib/tls/libc-2.3.2.so 293570 4.3139 0.0000 /usr/lib/libgobject-2.0.so.0.200.2 205231 3.0158 0.0000 /usr/lib/libgdk-x11-2.0.so.0.200.2 167575 2.4625 0.0000 /usr/lib/libglib-2.0.so.0.200.2 123095 1.8088 0.0000 /lib/libcrypto.so.0.9.7a 105677 1.5529 0.0000 /usr/X11R6/bin/XFree86 …
Когда вы формируете отчёт интерактивно, лучше применять less, так как отчёты могут содержать сотни строк. Именно поэтому приведённый здесь пример был сокращён.
В данном конкретном отчёте для каждого исполняемого файла, с которым связаны выборки, отводится отдельная строка. Каждая строка имеет следующий формат:
<sample-count> <sample-percent> <unused-field> <executable-name>
Где:
<sample-count> представляет число полученных выборок
<sample-percent> представляет процентное отношение выборок этого исполняемого модуля к числу всех выборок
<unused-field> — неиспользуемое поле
<executable-name> представляет имя файла исполняемого кода, для которого были получены выборки.
Этот отчёт (полученный в практически незагруженной системе) показывает, что в половине всех выборок процессор выполнял код самого ядра. Следующим был демон сбора данных OProfile, а за ним следовали различные библиотеки и сервер системы X Window, XFree86. Следует заметить, что для системы, использованной в этом пробном сеансе, значение 6000 — это минимальное значение счётчика, рекомендуемое командой opcontrol --list-events. Это значит, что на накладные расходы OProfile расходуется максимум 11% процессорного времени (по крайней мере, именно в этой системе).
Замечания
| [1] | Старшие номера устройств можно определить, использую команду ls -l для вывода имени интересующего вас файла устройства в /dev/. Старший номер устройства указывается после имени группы владельца устройства. |
| [2] | Изменения нагрузки системы могут привести к отклонениям времени сбора данных на секунду или две. |
| [3] | В тех архитектурах компьютеров, в которых отсутствует оборудование мониторинга производительности, OProfile также может включить запасной механизм (так называемый TIMER_INT). |