Обработка текстов — одно из первых по значимости (после собственно вычислительных задач и управления приборами), приложениий компьютера. Важность этой задачи заключается не только в огромных возможностях, предоставляемых компьютером для набора и редактирования, но и в том, что и взаимодействие пользователя с системой, и хранение и обмен данными в системе зачастую происходят именно в текстовой форме.
Команды, с помощью которых пользователь «общается» с системой — это текст. Сколько бы не популяризовали и не навязывали графические интерфейсы, для серьезной и продуктивной работы, как правило, не обойтись без полноценного текстового диалога, так же как при серьезном и предметном разговоре сложно обойтись жестами и ответной мимикой.
Эффективная работа с текстом критична и для развития самих вычислительных и коммуникационных систем, поскольку сами программы в исходной своей форме — тексты. Для программ на интерпретируемых языках (например, языках оболочек) тексты являются и исполняемой формой, так что такие программы — тексты вдвойне. А типичная стандартизованная ОС почти наполовину состоит из «сценариев», т. е. программ, написанных на интерпретируемых языках и предназначенных для исполнения оболочкой.
Работа с текстами критична также для многих пользовательских приложений. Например, электронная почта — это текст. Однако помимо так называемого плоского текста (от англ. plain text), содержащего только алфавитные и пробельные символы а также символы конца строки, огромное значение имеет размеченный текст. В размеченном тексте присутствуют инструкции — теги (от англ. tag), — указывающие, как следует интерпретировать тот или иной фрагмент текста. Набор таких инструкций, предназначенных для представления данных определенного рода — это формат разметки. Посредством таких форматов представлены форматированный текст, векторная графика, ноты и т. п. (практически все данные, за исключением растровой графики, волнового представления звука и видеодорожек) — т. е. в основе своей они также являются текстом.
Даже картинки и звуковые файлы, размещенные в WWW, передаются незаметно для пользователя между машинами в закодированной текстом форме, хотя в данном случае текст и не является «собственной» формой представления данных.
Хотя существуют и исключения. В некоторых случаях файлы настроек — тоже программы в широком смысле этого слова — представлены не текстом, а базой данных более сложной структуры. Программы с графическим интерфейсом могут содержать значительные фрагменты, первичной формой представления которых является нетекстовая.
Открытые ОС предоставляют достаточно широкий инструментарий работы с текстовыми данными, включая интерактивное редактирование и потоковую обработку. Они важны как в системном, так и в прикладном плане. В частности, администрирование операционной системы в значительной части представляет собой текстовое редактирование сценариев и файлов с данными.
Когда компьютеры были большими и дорогими, задача редактирования программ и других текстов решалась гораздо более простыми устройствами, обычно состоявшими из телетайпа (или клавиатуры) и перфоратора, фиксирующего вводимый текст на картах или ленте. Программы и данные записывались первоначально на бумаге и тщательно проверялись вручную: синтаксическая ошибка или ошибка формата могла обойтись в лишний прогон, зачастую это означало бесплодно потраченные дорогие часы машинного времени.
С удешевлением компьютерной техники и разработкой многопользовательских систем появилась возможность посадить оператора за подключенный к машине телетайп, где он свободно вводил и исправлял текст, а компьютер тратил основную часть своих ресурсов на обслуживание других пользователей или выполнение долгих пакетных заданий. Для удобства операторов (часто ими оказывались сами программисты) разрабатывались программы редактирования текстов (или, попросту, текстовые редакторы), как правило, выводившие текст построчно и ожидавшие клавиатурной команды (зачастую на особом изощренном языке), сообщающей, следует ли оставить строку неизменной, либо внести в нее какие-то изменения.
Следующий шаг был сделан, когда телетайп (электрическую пишущую машинку) в качестве терминального устройства сменил дисплей с электронно-лучевой трубкой. Это превратило текст перед глазами оператора в динамический и позволило совершить революцию в редактировании текстов, внедрив так называемые «полноэкранные» (или, просто «экранные») редакторы, взаимодействуя с которыми оператор получил возможность, хотя и манипулируя клавиатурой, применять технику, скорее похожую на приемы работы с листом бумаги писателя, возвращающегося к ранее написанному, стирающего и исправляющего текст нелинейно.
Два, по-видимому, первых экранных редактора, созданных в начале семидесятых, и явились родоначальниками «семейств» таких программ, до сих пор наиболее популярных в профессиональной среде. Это vi (читается «ви-ай») Билла Джоя (тогда аспиранта Университета Калифорнии в Беркли, а затем основателя Sun Microsystems) и emacs (читается «и-макс») Ричарда Столлмена (тогда сотрудника Лаборатории искусственного интеллекта Массачуссетского технологического института, а ныне — президента Фонда свободного программного обеспечения и лидера проекта GNU). Оба они, по сути, происходят от экранных режимов работы популярных тогда редакторов ed и TECO, соответственно.
Первый ныне стандартизован и, в той или иной реализации (наиболее популярна, видимо, vim Брама Мооленаара) доступен в составе любой стандартной операционной системы (в том числе, свободных), а также — отдельно — для многих альтернативных ОС. Второй под названием GNU Emacs поддерживается и выдержал уже более двадцати изданий (релизов), он обычно входит в поставки ОС GNU/Linux и доступен для прочих (открытых и альтернативных) ОС.
Исходная идеология и эргономическая модель этих двух выдающихся разработок несколько различается, что служит поводом для шутливой «священной войны» между их приверженцами. vi(m) относится к так называемым «многорежимным» редакторам. В режиме редактирования оператор вводит и исправляет текст. Перемещение по тексту, контекстный поиск и замена, более сложные операции выполняются в командном режиме. Между этими режимами (а также редко применяющимся режимом построчного редактирования) нужно явное переключение нажатием клавиатурной комбинации. Зато большинство команд привязаны к нажатиям одной клавиши, и даже перемещаться по тексту в командном режиме можно, не сбрасывая кисть руки на дополнительную клавиатуру со стрелками, а нажимая алфавитные клавиши в центре клавиатуры. Адепты vi — программисты и системные администраторы — очень серьезно относятся к экономии времени и энергии за счет минимизации движения пальцев.
emacs — пример «безрежимного» или, если угодно, «однорежимного» редактора: пользователь всегда находится в режиме непосредственного редактирования текста в точке курсора, а команды издает, нажимая сложные сочетания клавиш и, при необходимости, вводя параметры команд в отдельном окне. Из-за стремления обеспечить прямую клавиатурную привязку как можно большему количеству команд и следующей из нее сложности используемых клавиатурных сочетаний был даже пущен слух о том, что emacs расшифровывается как Esc-Meta-Alt-Ctrl-Shift (хотя на деле, конечно, клавиатурные аккорды все же не так сложны, а emacs — это просто «Editing MACroS», т.е. «макрокоманды редактирования»).
В действительности, различие это скорее идеологическое, чем прагматическое: в современных версиях vi в большинстве случаев также можно осуществить привязку часто употребляемых команд к клавиатурным комбинациям и выполнять их из режима редактирования, а в emacs можно достаточно точно (если кому-то это потребуется) имитировать командный режим, характерный для многорежимных редакторов.
Реальное очень значимое отличие заключается в том, что по своей архитектуре vi — более или менее монолитная программа (с вытекающей отсюда компактностью), а emacs — на самом деле, расширяемая (программируемая) коллекция макрокоманд редактирования, написанных на Emasc Lisp (диалекте известного языка функционального программирования). Лишь интерпретатор самого Emacs Lisp и небольшое количество часто выполняемых (и требовательных к ресурсам) команд встроены в саму программу и написаны на компилируемом C, большинство же команд написаны на Lisp и могут изменяться или дополняться пользователями (или профессиональными программистами по заказу пользователей).
За четверть века существования emacs, благодаря свободной модели лицензирования и открытой модели разработки, «оброс» невероятным количеством макрокоманд, «затачивающих» его под синтакcические особенности различных формальных языков (включая, но не ограничиваясь языками программирования и языками разметки), а также реализующих приложения, традиционно слабо ассоциируемые с «просто редакторами». Например, не выходя из emacs, можно работать с электронной почтой и службами новостей USENET (а также с гипертекстом со страничек WWW).
Или — что не менее интересно — не выходя из emacs, можно прогнать текст программы через компилятор и подсветить синтаксические ошибки или предупреждения, воспользоваться символьным отладчиком или профилировщиком (реально, emacs образует оболочку интегрированной среды разработки программ, и в этом качестве является вдохновителем и предшественником всех прочих интегрированных сред разработки (IDE)). И это лишь пара примеров.
Фактически, регулярно используемый emacs позволяет реализовать (чисто в текстовом режиме, даже в системах, вообще не поддерживающих графику) метафору «рабочего стола», более известную по позднейшим графическим пакетам. Он реализует множественность окон (неперекрывающихся) на одном экране («фрейме»), а в графической среде способен работать со многими «фреймами» (окнами в терминах менеджера окон). Пакет Emacspeak добавляет к функциональности emacs речевой вывод, предоставляя мощную поддержку для незрячих и слабовидящих пользователей[15].
Все это (доступность, расширяемость, интегрируемость) делает его серьезным претендентом на организацию «учебного» рабочего пространства программиста (и, на самом деле, есть университетские курсы, так и построенные). Можно ли это использовать в сегодняшней школе?
Однозначного ответа на этот вопрос у нас нет. Дело в том, что нам неизвестны такие (ориентированные на среду на основе emacs) курсы для школ вообще. А что касается России (и русскоязычного сообщества), то нам неизвестны примеры школьных курсов, вводящих на достаточно раннем этапе идеи функционального программирования. А без последнего — увы — расширяемость emacs остается чисто теоретической.
Однако в качестве интегрированной среды именно для программирования (в том числе, на обычно изучаемых в школе директивных языках, например, Pascal) emacs использовать, безусловно, можно. Следует только учесть, что пресловутая «кривая обучения» для него гораздо более вогнутая, чем для более простых (но и менее мощных) средств редактирования, обычно используемых в подобного рода средах. Грубо говоря, может потребоваться пара занятий до того, как учащийся будет чувствовать себя уверенно при наборе и редактировании программ, зато потом эти задачи будут решаться гораздо эффективнее. (Кривую обучения можно сгладить, создав дополнительный набор макрокоманд под конкретный курс и, наверное, это правильный способ, но он потребует от методиста незаурядного знания не только emacs, но и Emacs Lisp.)
В обычных учебных курсах vi изучается раньше emacs. Такая структура заимствуется из традиционного курса подготовки администраторов и продвинутых пользователей открытых систем. Дело в том, что vi, во-первых, стандартизован (и доступен во всех без исключения открытых системах), а во-вторых, компактен. Администратор системы может оказаться (например, при восстановлении после сбоя) в среде, где ему из экранных редакторов доступен только vi. Поэтому для сисадминов базовые навыки работы с ним обязательны (вне зависимости от личных предпочтений).
В учебной обстановке, не ориентированной на профессиональную подготовку, такого императива, полагаем, нет, поэтому методисты и преподаватели вольны выбрать наиболее адекватный инструмент для демонстрации возможностей текстовых редакторов, если задача состоит только в знакомстве учащегося с таковыми. Выбор огромен, но остановится он, скорее всего, или на vi, или на emacs.
Далеко не всегда открывать файл и редактировать его вручную является оптимальным способом работы с содержащимся в нем текстом. Чем более формализован текст, и чем более типовым является редактирование, которое необходимо выполнить, тем больше шансов, что существует способ «малой кровью» оптимизировать этот процесс. Рассмотрим очень формальную задачу.
В мае 2001 г. в Кремле состоится встреча с ветеранами Великой отечественной войны.
В мае 2001 г. в Кремле состоится встреча с ветеранами Великой отечественной войны. Откроет встречу Президент Российской Федерации Борис Ельцин. ~ ~ ~ -- INSERT -- 3,1 All
Допустим, в файле note сохранен текст записки:
В мае 2001 г. в Кремле состоится встреча с ветеранами Великой отечественной войны.
Откроет встречу Президент Российской Федерации Борис Ельцин.
Если ситуация изменилась (и мы отдаем себе отчет, как именно), можно открыть файл с этим текстом в текстовом редакторе, например, vi, и издать команду:
:s/Борис Ельцин/Владимир Путин/g
Текст (предсказуемо) приобретет вид:
В мае 2001 г. в Кремле состоится встреча с ветеранами Великой отечественной войны. Откроет встречу Президент Российской Федерации Владимир Путин.
Однако, то же самое действие можно выполнить и «без редактора», а точнее, без интерактивного редактора, с помощью редактора потокового. Стандартный потоковый редактор называется sed, и синтакис его команд схож с синтаксисом командного режима стандартного интерактивного редактора vi, команда при этом издается непосредственно из командной строки:
$sed -n 's/Борис Ельцин/Владимир Путин/g' note
Если у нас подготовлен не один файл, а множество (например, note.1, note.2, note.3), и нужно внести в них единообразные замены (и ничего не пропустить, и нигде не ошибиться), мы обойдемся также всего одной командой.
$sed -n 's/Ельцин/Березовский/g' note.*
Если файлов будет тысяча, а требуемые изменения будут посложнее, нам, скорее всего, понадобится опять-таки всего одна команда (хотя, возможно, и потребуется серьезное изучение синтаксиса). Это называется потоковым редактированием, и оно интенсивно применяется, например, для наложения «заплаток» на исходные тексты программ (однако, как было продемонстрировано, с успехом может использоваться и для обработки текста на естественном языке).
ОС UNIX была во многом «рождена для обработки текстов» (прежде всего, это была система для программистов, а программы — это тексты). Набор служебных программ (утилит) современных стандартных ОС продолжает эту традицию, и в их составе можно найти десятки программ, ориентированных на работу с текстом. Многие из них (но не все) являются построчно-ориентированными, то есть текст понимается как последовательность строк.
Команда grep выводит строки, содержащие заданную подстроку, команда sort сортирует строки по алфавиту, uniq удаляет неуникальные (дублирующиеся) строки, split разделяет файлы, cat соединяет и т.п. Подробное описание команд потоковой обработки текста может занять отдельную толстую книгу.
В стандартной операционной среде отдельные утилиты могут «склеиваться» с помощью рассмотренных выше штатных средств оболочки операционной системы (перенаправление ввода-вывода, конвейер), что позволяет гибко решать самые сложные задачи обработки текстов, не прибегая к программированию на специальных языках, компилированию и сборке программ.
Многими стандартными утилитами (такими как sed, grep, vi) для поиска, замены, выбора текста, используются базовые регулярные выражения.
Регулярное выражение — это последовательность символов. При использовании (передаче в качестве аргумента программе или вводе в ходе сеанса редактирования) регулярное выражение (шаблон) обычно[16] окружается ограничителями — двумя одинаковыми символами, обозначающими его начало и конец, но не являющимися частью самого выражения. За исключением особых случаев в качестве ограничителей принято брать прямую косую черту (/, слэш), она окружает выражения и во всех нижеприведенных примерах.
Сами же символы могут (в зависимости от значения и, иногда, положения) иметь прямое (буквальное) значение или специальное. Символ-ограничитель не может употребляться внутри выражения в буквальном значении; также не рекомендуется использовать в этом качестве любой из перечисленных ниже специальных символов.
В буквальном значении символ автонимен, т. е. обозначает сам себя. /а/ обозначает букву «а», /слово/ означает слово «слово».
В синтаксисе базовых регулярных выражений определены следующие специальные символы.
-
Любой одиночный символ обозначается точкой (
.), а не вопросительным знаком, как при «глоббинге» имен файлов. -
Квадратные скобки (
[и]) так же, как и при «глоббинге», используются для задания списков и диапазонов. -
Знак каретки (
^) имеет специальное значение в первой позиции внутри квадратных скобок. В этом случае он означает отрицание:/[А-Яа-я]/соответствует «любой букве русского алфавита», а/[^А-Яа-я]/— «любому символу, кроме букв русского алфавита». Чтобы включить его в список, достаточно поместить его в любую другую позицию:/[~`^]/— это «тильда, апостроф или знак каретки». -
Специальные значения, которые слишком сложны, чтобы их здесь рассматривать, в первой позиции внутри квадратных скобок имеют также: точка (
.), знак равенства (=) и двоеточие (:). -
Каретка в начале выражения означает начало строки:
^Tнайдет заглавноеТ, начинающее строку. Подобно этому знак доллара ($) в конце выражения означает конец строки. -
Звездочка тоже используется в значении «нуля или более вхождений символа», но по-другому — для этого она должна следовать за таким символом. Шаблон
/A*/соответствуетA,AA,AAAи т.д. Звездочка может следовать и за выражением, например,/[А-Яа-я]*/означает «любую последовательность букв русского алфавита». Любая последовательность любых символов может быть обозначена/.*/. -
Обратная косая черта (
\, «бэкслэш») «экранирует» следующий за нею символ, то есть отменяет его специальное значение./\./означает точку,/\*/— звездочку, а/\\/— обратную косую черту. Обратная косая черта, за которой следует цифра, также имеет специальное значение, которое здесь не рассматривается.
Кроме того, регулярные выражения могут включать скобочные конструкции. В качестве скобок используются последовательности \( и \) (это совершенно нелогичное обратное (не отменяющее специальное значение следующего символа, а, наоборот, придающее ему специальное значение) значение бэкслэша обусловлено чисто историческими причинами: скобочные выражения вводились в синтаксис регулярных выражений, когда он уже устоялся). Например, шаблон /\(аб\)*/ соответствует строкам аб, абаб, абабаб и т. д. Скобочные конструкции могут быть вложенными.
Водораздел между текстовыми редакторами и word-процессорами проходит по критерию способа отображения размеченного (имеющего некоторые атрибуты, такие, как цвет, начертание и кегль (размер) символов, выключка (выравнивание) и расположение абзацев, оформление страницы и т. п.) текста. Текстовый редактор отображает его как есть, например:
<курсив>Предложение, набранное курсивом.</курсив>
а word-процессор визуализирует эти атрибуты, например:
Предложение, набранное курсивом.
Визуализацию иногда путают с так называемым WYSIWYG-принципом (сокращение от «What you see is what you get» — «Что видишь, то и получишь»).
Однако в общем случае это неверно: WYSIWYG-идеология унаследована от эпохи персональных компьютеров, когда в ходе «малой компьютеризации» отдельные офисы и рабочие места становились «островами» безбумажных технологий в море бумажной коммуникации, и компьютерное представление мыслилось лишь промежуточной или предварительной формой существования текста или документа.
Сегодня большинство документов никогда не попадает на принтер, и нет нужды подстраиваться под архаичный бумажный документооборот. Вполне возможно, что автору или редактору удобнее выделение не курсивом, а подчеркиванием:
Предложение, набранное курсивом.
Более того, современные технологии (например, HTML или XML-оформление текстов) изначально предполагают, что читатель документа может устанавливать собственные предпочтения в визуализации, зависящие от особенностей используемого им оборудования (размеров и разрешающей способности монитора и т. п.) или от своих биологических особенностей (слабого зрения, дальтонизма и т. п.), и в общем случае они могут не совпадать с предпочтениями автора или редактора.
Таким образом, один и тот же документ может быть отображен с разметкой, с визуализацией, а иногда — и с разметкой и с визуализацией (см. рис. 3.1).
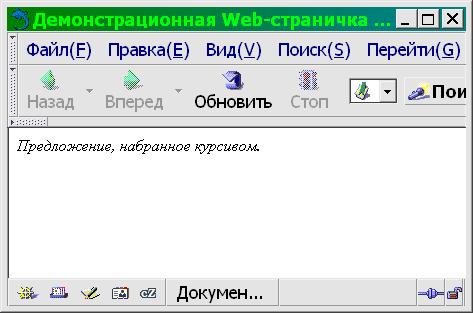
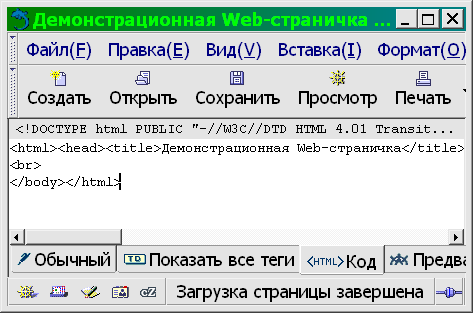
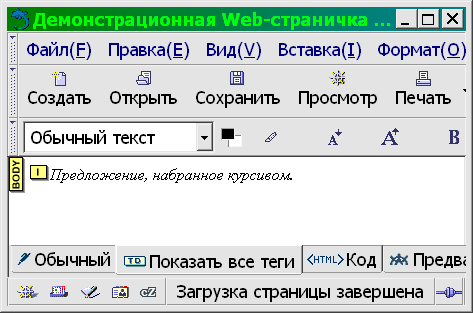
Хотя на рисунке нам удалось показать три типа отображения одного и того же документа, не выходя из одного прикладного пакета, это не такой частый случай. На самом деле текстовые редакторы, как правило, не имеют способности непосредственной визуализации вообще или обладают ею лишь в зачатке (как, например, Emacs, способный визуализировать формат Enriched text, но Emacs это не просто редактор, а целая операционная среда), а word-процессоры, в свою очередь, крайне неудобны для редактирования «плоского» текста: слишком разнятся базовая операторика и ожидаемая эргономика этих двух типов прикладных программ.
И «Обязательный минимум...», и большинство конкретных учебных планов предусматривает знакомство лишь с базовой функциональностью программ манипуляции текстами, и любой из свободных словарных процессоров (AbiWord, Kword, OpenOffice.org Writer) гарантированно и с избытком перекроет требования (так же, как и масса присутствующих на рынке несвободных программ, таких, как Microsoft Word, StarOffice или WordPerfect). Поскольку большинство из них так или иначе развивают основные интерфейсные подходы WordPerfect, существенного (и могущего быть выявленным в пределах тех немногих часов, что учитель в состоянии уделить этой теме) эргономического различия между ними нет.
Значит основания для рационального выбора программы нужно искать не внутри темы манипулирования текстами, а в ее связи с другими учебными темами. У программистов есть такой эмпирический принцип: когда начинаешь путаться в программах, отложи их в сторону и попытайся разобраться со структурами данных — сам удивишься, насколько очевидными и простыми окажутся после этого решения, касающиеся программ. Возможно, этот принцип разумно применять и пользователям.
Учащийся сталкивается с задачей манипулирования «плоским» текстом как минимум два раза (при знакомстве с электронной почтой и при изучении основ программирования), соответственно, успевает познакомиться, как правило, с двумя разными текстовыми редакторами (встроенными в почтовую программу и среду программирования, соответственно). Как минимум два раза он сталкивается и с задачей манипулирования размеченным текстом: один раз его знакомят с word-процессором (как правило, в России под руку подворачивается «пиратский» Microsoft Word, либо бесплатно распространяемый StarOffice, исключения единичны), а затем ему преподносят основы HTML.
Знакомство с манипулированием текстом, таким образом, оказывается бессистемным и фрагментарным, и, в лучшем случае, автор учебника или учитель сумеют рассказать о том, что сфера это, в общем-то единая, а показать это оказывается весьма затруднительно.
Значительным шагом к систематизации опыта, вырабатываемого школьным курсом, на наш взгляд, является использование инструментария, позволяющего демонстрировать возможность работы с размеченным текстом разными средствами. Это значит, что к очевидным требованиям, предъявляемым к «учебному» word-процессору (достаточность функций, локализованность, мультиплатформенность, ценовая доступность), добавляется серьезное пожелание: стандартность формата разметки.
Это сильно облегчает выбор. На самом деле, на сегодня всем перечисленным требованиям удовлетворяет, по сути, лишь одна программа. Но сначала — немного о стандартах.
Существуют и доказали свою устойчивость два основных типа языков разметки.
Первый из них, это семейство, называемое *ML-языками: на эти две буквы заканчиваются аббревиатуры их названий — GML, SGML, HTML, XML, — а сами по себе эти буквы означают просто «markup language» — «язык разметки».
Второй — разработанный выдающимся американским теоретиком и практиком программирования Дональдом Кнутом язык программирования верстки TeX[17] и его расширения (например, LaTeX). Не будучи официальным стандартом, ТеХ постепенно вытесняет и замещает прочие языки разметки, предназначенные для набора и верстки текстов (TeX и системы на его основе плохо приспособлены для верстки т.н. «иллюстрированных изданий» с характерным для них богатым насыщением текста графикой, сложными обводами и наложениями текста на графику и пр., и этот сегмент рынка остается пока не стандартизованным).
За пределами этих типов — огромное множество нестандартных (и даже неопубликованных) форматов, зачастую использующих не текстовую, а двоичную форму представления данных (например, файлы Microsoft Word и т. п.). Это исключает возможность применения для работы с такими данными обычных текстовых редакторов и обработку их стандартными текстовыми утилитами, а также сильно затрудняет обратную разработку формата с целью обеспечения импорта и экспорта из независимо написанных программ[18].
Наверное, TeX имеет потенциал к использованию в качестве примера языка разметки (или, точнее, языка генерации разметки), однако вряд ли в средней школе — отчасти потому, что ориентирован на печатную форму в качестве окончательной формы представления содержания, что представляет на сегодня если не экзотическую, то, во всяком случае, достаточно специальную область применения компьютеров, в отличие от *ML-языков, в равной степени ориентированных и на «экран», и на «бумагу».
SGML достаточно давно (с 1986 г.) является стандартом на разметку документов, принятым Международной организацией стандартизации (серия ISO 8879). Парадокс заключается в том, что до недавнего времени даже частичные реализации SGML были сравнительно немногочисленными, и его использование ограничивалось рамками государственных организаций (в массе своей оборонных и научных) и крупных корпораций. Гораздо более широкое распространение получили «похожие на SGML» языки, а именно, HTML различных версий, являющийся одним из технологических столпов WWW.
HTML был сознательно создан как «игрушечный SGML»: он не обладал всей гибкостью и мощью последнего, но был очень компактен и легок в реализации и изучении. Одна из сторон «игрушечности» HTML заключается в том, что он подталкивает пользователя к использованию физической, а не логической разметки, и именно поэтому, на наш взгляд, его не стоит изучать в школе.
Однако добавление все новых и новых возможностей и конструкций в HTML в ходе его развития привело к тому, что сложность его существенно выросла и приблизилась к сложности SGML-приложений, при сохраняющейся несовместимости с SGML.
Параллельное развитие двух близких по назначению языков было очевидно нецелесообразным, поэтому дальнейшее развитие WWW предполагает переход на XML — «расширяемый язык разметки», который превосходит по мощности, гибкости и согласованности HTML и является полноценным SGML-приложением. Уже сегодня наиболее развитые WWW-серверы генерируют HTML именно из XML непосредственно «понимать» последний постепенно учатся и браузеры.
На наш взгляд, принципы расширяемой разметки, реализованные в XML, могут и должны стать одной из базовых составляющих компьютерной грамотности и обязательно должны найти свой путь в школьные учебные планы. Это позволит:
-
подвести единую основу и логически связать такие темы, как манипуляция размеченным текстом, гипертекстом и гипермедиа, векторной графикой, электронными таблицами и т. п.,
-
приблизить школьную информатику к реальным тенденциям развития информатики и информационной отрасли вообще, вывести ее из закутка «персонального компьютинга»,
-
упростить за счет стандартизации задачу выбора (разработки) учебных программ и пакетов.
Задача доступного изложения основ XML и приемов работы с ним сама по себе непроста, как дидактически, так и технически (в частности, нужны определения типов документов (DTD) для учебных задач, достаточно развитые для демонстрации возможностей языка, но в то же время достаточно простые для понимания XML-документов «с листа» и низкоуровневого редактирования).
Однако одно из основных препятствий на пути использования XML в школе — неразвитость визуализирующих редакторов — уже отпало с появлением офисного пакета OpenOffice.org. Он сочетает привычные пользователям ПК пользовательские интерфейсы с поддержкой стандартных XML-приложений, таких, как «текстовый документ» (программа OpenOffice.org Writer), «электронная таблица» (OpenOffice.org Calc), «презентация» (OpenOffice.org Impress), «формула» (OpenOffice.org Math), «гипертекст» (OpenWeb) и, что уже совсем не характерно для «офисного» софта, «векторный рисунок» (OpenOffice.org Draw), их взаимного внедрения и связывания.
По сути дела, OO.o — это «троянский конь», заброшенный в мир «малой компьютеризации»: «снаружи» он похож на «офис», а «изнутри» (или «с изнанки») представляет собой набор XML-инструментов. «Офисной» стороной он обращен к опыту пользователей персональных компьютеров, инструментальной — к современным, постперсональным вычислительно-коммуникационным системам (включая локальные сети и сети Интернет с возможностями безбумажного документооборота и совместной работы над документами).
Важно отметить, что для пакета приграмм OO.o «родным» форматом зранения данных является открытый, стандартизированный формат ODF (сокращённое от OASIS Open Document Format for Office Application).
ODF — открытый формат документов для офисных приложений, в том числе текстовыми документов (таких как заметки, отчёты и книги), электронных таблиц, рисунков, баз данных, презентаций.
Стандарт был разработан индустриальным сообществом OASIS и принят как международный стандарт ISO/IEC 26300. Стандарт был совместно и публично разработан различными организациями, доступен для всех и может быть использован без ограничений. OpenDocument представляет собой альтернативу частным закрытым форматам, включая DOC, XLS и PPT (форматы используемые в Microsoft Office), а также формату Microsoft Office Open XML.
| Вид документа | Расширение |
| Текстовый документ | odt |
| Текстовый документ, используемый как шаблон | ott |
| Графический документ | odg |
| Графический документ, используемый как шаблон | otg |
| Документ презентации | odp |
| Документ презентации, используемый как шаблон | otp |
| Электронная таблица | ods |
| Электронная таблица, используемый как шаблон | ots |
| Документ диаграммы | odc |
| Документ диаграммы, используемый как шаблон | otc |
| Документ изображения | odi |
| Документ изображения, используемый как шаблон | oti |
| Документ формулы | odf |
| Документ формулы, используемый как шаблон | otf |
| Составной текстовый документ | odm |
| Текстовый документ, используемый как шаблон для HTML-документов | oth |
Пользователи, сохраняющие свои данные в открытом формате, таком как OpenDocument, избегают опасности быть загнанными в угол единственным поставщиком ПО, они свободны выбрать другое программное обеспечение, если их сегодняшний поставщик уйдёт с рынка, поднимет цены, изменит своё программное обеспечение или изменит условия лицензионного соглашения на более строгие.
OpenDocument является единственным стандартом для редактируемых офисных документов, утверждённым независимым комитетом по стандартам и реализованным несколькими поставщиками программного обеспечения. OpenDocument может быть использован любым поставщиком ПО, включая, в том числе, поставщиков закрытого программного обеспечения и разработчиков использующих GNUGPL.
OpenOffice.org Writer (далее — OW) — это название word-процессора из комплекта свободных офисных прикладных программ OO.o[19].
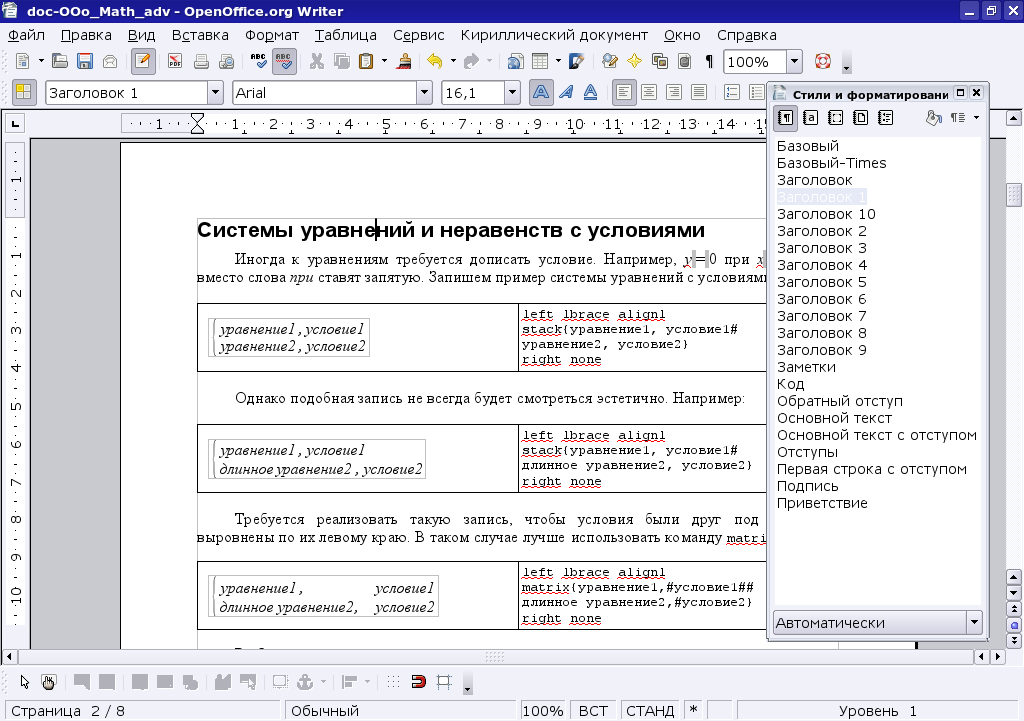
Как уже говорилось выше, все словарные процессоры внешне (по функциональности и интерфейсу) похожи друг на друга, и OW (см. рис. 3.2) — не исключение. Он предназначен для набора, редактирования и оформления текстов на естественных языках (включая многоязычные) и поддерживает:
-
физическое и логическое (через механизм стилей) форматирование документа в целом, отдельных страниц, разделов, абзацев и символов;
-
шаблоны (наборы стилей и формы документов);
-
лингвистическую поддержку (корректные переносы, проверку орфографии и грамматики, тезаурус (русского грамматического и тезаурус-модулей пока нет));
-
внедрение и связывание объектов — как из XML-приложений, так и чужеродных (включая растровую графику и результаты выполнения запросов к базам данных);
-
импорт/экспорт унаследованных нестандартных форматов (в базовую поставку входит модуль только для Microsoft Office), а также плоско-текстовых и гипертекстовых форматов;
-
встроенный макроязык;
-
автоматическую нумерацию элементов, оглавления и указатели;
-
... (назовите сами).
За подробностями отсылаю к [6-9].
Интересное, однако, начинается, когда мы посмотрим на OW «с изнанки». Файлы с расширением имени .odt, создаваемые им — это PKZIP-архивы, содержащие (в простейшем случае) набор XML-файлов, соответствующих (в терминах XML) манифесту, содержанию документов, определению стилей и значениям текущих настроек.Заглянем в файл с содержанием (content.xml). Даже не зная XML, и лишь ориентируясь в синтаксисе языка разметки, можно понять, что файл содержит сначала определения стилей, использованных в документе (даже «жесткое» форматирование имитируется в OW путем создания неявных стилей), а затем размеченного указаниями на эти стили текста. Заголовок статьи размечен так:
<text:p text:style-name="P2"> <text:span text:style-name="T1"> Лекция 0. </text:span> <text:span text:style-name="T2"> OpenWriter — </text:span> <text:span text:style-name="T3"> свободный </text:span> <text:span text:style-name="T2"> word- </text:span> <text:span text:style-name="T3"> процессор </text:span> </text:p>
Понятно, что для форматирования использован один стиль абзаца P2 и три стиля символов T1, T2 и T3. Выше, в определениях стилей можно найти, что, допустим, T2 — это стиль, определенный в вышеприведенном примере.
<style:style style:name="T2" style:family="text"> <style:properties fo:font-weight="bold" style:font-weight-asian="bold" style:font-weight-complex="bold"/> </style:style>
То есть «текстовый» (символьный) стиль, предполагающий набор и отображение полужирным шрифтом.
Теперь content.xml может обрабатываться любым XML-инструментом уже без использования OO.o. Его можно преобразовать в HTML или проиндексировать, вывести на печать, просмотреть браузером, поддерживающим XML. Произвольные определения документов напрямую пока браузерами не поддерживаются, однако текст (неформатированный) можно уже сегодня просмотреть, просто открыв content.xml в Mozilla Firefox; или другом браузере, поддерживающем XML.
Приемы работы с текстом — неотъемлемая часть компьютерной грамоты, но слишком часто она оказывается не освоенной вовремя. К сожалению, зачастую в курсе средней школы знакомство с обработкой плоских текстов ограничивается встроенными редакторами в среде программирования и электронно-почтовой программе, а навыки — простейшими приемами набора и исправления. Более абстрактные и всеобщие операции изучаются как часть word-процессинга, и хотя иногда при этом и демонстрируются возможности встроенных в word-процессоры языков программирования, область обработки текстов остается «вещью в себе» и никак не интегрируется с другими областями, осваиваемыми в курсе информатики.
Отказаться вовсе от работы с «плоским» текстом затруднительно по давно известной эргономистам причине: использование визуализации «позволяет демонстрировать лишь результат форматирования, по нему невозможно определить задачи форматирования, поставленные пользователем системе. Например, если пользователь замечает, что система не делает переносов ... невозможно определить ... является ли это простым совпадением или же при форматировании данной главы перенос запрещен»[20].
[15] Функциональность Emacspeak пока доступна лишь англоязычной аудитории.
[16] Исключением являются утилиты семейства grep.
[17] Это греческий корень, он читается как русское «тех», а не как «текс».
[18] Возможно, использование двоичных форматов и было оправданно во времена, когда позволяло экономить байты памяти и носителей на «персоналках» с крайне ограниченными аппаратными ресурсами. В то же время, современные компьютеры (даже относимые к классу персональных, «стартового уровня») обладают ресурсами, позволяющими организовать гораздо более удобную схему: сжатие «на лету» по стандартному алгоритму стандартно размеченного текста или иных данных.
[19] «В девичестве» (до того, как американская корпорация Sun Microsystems приобрела немецкую компанию StarDivision и свободно лицензировала код, права на который принадлежали ранее последней) пакет назывался StarOffice, а word-процессор — StarWriter; под таким названием он получил известность и обрел достаточную популярность, в том числе, и в России (особенно версии 5.1 и 5.2).
[20] Робертс Т. Текстовые редакторы // Человеческий фактор. Т. 6. — М.: Мир, 1992.